Links: OBS site w/forums
A high-speed internet connection is foundational for streaming, but what are some other considerations? Some live stream sites (YouTube, Discord, Glimesh) will need an OBS type app on the user's system to format a stream to transmit to their site. Other sites (Zoom) have a proprietary streaming app, but the app experience can sometimes be enhanced by routing it through an OBS-type app. A third issue is the various streaming protocols and site authentications. A fourth issue is hardware problems which can be specific to a streaming app. All this complexity allows for multiple problems and solutions.
Note: a fifth issue is that OBS is natively setup for the notorious Nvidia hardware and the PulseAudio software. Detection of audio is particularly difficult without PulseAudio, eg requiring JACK config.
protocols and authentication
RTMP streaming providers typically require a cell number via the "security" (forensic record) requirement of 2FA requiring a cell. This is an immense safety issue. Who knows how these providers tie cell numbers to credit reports, "trusted 3rd parties", etc? The answer is consumers are expected to understand a multi-page "privacy" policy filled with legalistic language and equivocations, which regularly changes, and which varies from site to site. Way to protect us Congress, lol. Accordingly, since I essentially have no idea what they're doing with my cell, I try to avoid streaming services which require a cell.
Although they require a cell*, YouTube's advantage is streaming directly from a desktop/laptop with nothing beyond a browser. Discord can do similarly with limited functionality, and they have a discord app which adds features. Glimesh works well with OBS -- it provides a stream key for OBS, or whatever a person is using.
*YouTube requires "account verification" at https://www.youtube.com/verify prior to streaming. The verification is 2FA to a cell.
obs
Those not intending to use OBS can still find utility in its attempts to stream or record. A great deal will be revealed about one's system. OBS logs are also valuable to identify/troubleshoot problems, eg the infamous
'ftl_output' not found issue -- you'll find it in the logs (~/.config/obs-studio/logs). OBS can encounter a couple of problems.
obs hardware issue: nvidia graphics card
Obviously, no one wants NVidia hardware: the associated bloatware is almost unbearable. However, its use is so common that many users have it in their system(s). OBS therefore makes Nvidia the default. This setting spawns errors for systems with AMD Radeons. Change the "NV12" (or 15 by now) circled below to an option which works for one's hardware.
1. obs audio problem - alsa and jack
Most desktops unfortunately have two audio systems: an MB chip, and a graphics card chip. Difficulty can arise when one source is needed for mic input, and the the other source is needed for playback (eg, for HDMI). This is bad enough. However there's an additional problem with OBS -- it doesn't detect ALSA. Your options are PulseAudio (gag), or JACK (some config work, depending). I end up using a modified PulseAudio. More about that here.
1. obs local configuration and usage: to MP4
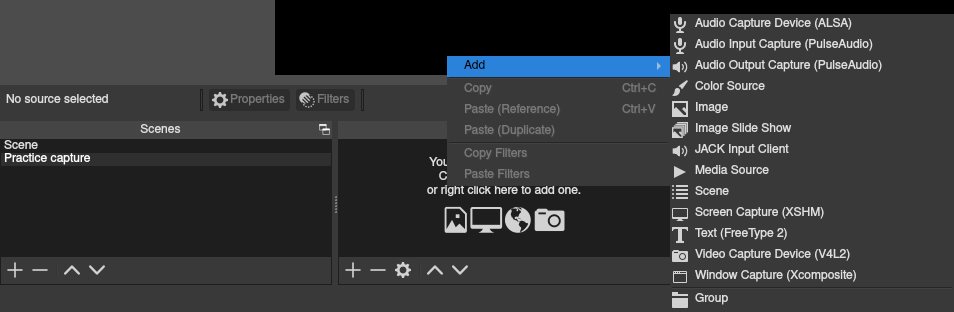
Fffmpeg works great for screen and input captures, but OBS can be preferable for more mixing in during live. In OBS terminology "scenes" and "sources" are important words. Scenes is a collection of inputs (sources). OBS is good at hardware detection, but files can be played, websites shown, hardware (cams, mics), images (eg for watermarks) other videos, and so on. For making MP4's "Display Capture" is obviously an important source.
Scenes and Sources (8:08) Hammer Dance, 2021. How to add the scenes and sources to them.
V4L2 issues
1. loopback issue
Unimportant, though you might find it in the OBS logs
v4l2loopback not installed, virtual camera disabled.
The solution steps are here.
- v4l2loopback-dkms: pacman. basic loopback. This makes a module, so you need to do, pacman -S linux-headers prior to the loopback. install.
- v4l2loopback-dc-dkms: AUR. haven't tried this one. apparently allows connecting an Android device and using it as a webcam via wifi
We're not done because the loopback device will takeover /dev/video0, denying use of our camera. So we need to configure our loopback to run on /dev/video1. This has to be specified by putting a load-order file into /etc/modules-load.d/
.
Install the loopback, if desired.
# pacman -S v4l2loopback-dkms
2. ftl_output issue
This is one is important.
$ lsmod |grep video
uvcvideo 114688 1
videobuf2_vmalloc 20480 1 uvcvideo
videobuf2_memops 20480 1 videobuf2_vmalloc
videobuf2_v4l2 36864 1 uvcvideo
videobuf2_common 65536 2 videobuf2_v4l2,uvcvideo
videodev 282624 4 videobuf2_v4l2,uvcvideo,videobuf2_common
video 53248 3 dell_wmi,dell_laptop,i915
mc 65536 4 videodev,videobuf2_v4l2,uvcvideo,videobuf2_common
If we haven't installed loopback, then video0 is the default. Note this is verified by the lack of any settings or capabilities returned on video1.
$ v4l2-ctl --list-devices
Integrated_Webcam_HD: Integrate (usb-0000:00:14.0-2):
/dev/video0
/dev/video1
/dev/media0
$ v4l2-ctl -l -d 0
brightness 0x00980900 (int) : min=-64 max=64 step=1 default=0 value=0
contrast 0x00980901 (int) : min=0 max=95 step=1 default=0 value=0
saturation 0x00980902 (int) : min=0 max=100 step=1 default=64 value=64
hue 0x00980903 (int) : min=-2000 max=2000 step=1 default=0 value=0
white_balance_temperature_auto 0x0098090c (bool) : default=1 value=1
gamma 0x00980910 (int) : min=100 max=300 step=1 default=100 value=100
gain 0x00980913 (int) : min=1 max=8 step=1 default=1 value=1
power_line_frequency 0x00980918 (menu) : min=0 max=2 default=2 value=2
white_balance_temperature 0x0098091a (int) : min=2800 max=6500 step=1 default=4600 value=4600 flags=inactive
sharpness 0x0098091b (int) : min=1 max=7 step=1 default=2 value=2
backlight_compensation 0x0098091c (int) : min=0 max=3 step=1 default=3 value=3
exposure_auto 0x009a0901 (menu) : min=0 max=3 default=3 value=3
exposure_absolute 0x009a0902 (int) : min=10 max=626 step=1 default=156 value=156 flags=inactive
$ v4l2-ctl -l -d 1
[nothing]
However, even with this default correct, there is a ftl_output error remaining which prevents an output video stream.
$ yay -S ftl-sdk
plug-ins
OBS has plugins, for example one that
shows keystrokes and mouse clicks.
Streaming and Recording(11:08) Gaming Careers, 2019. OBS based tutorial, using the computer, not a capture card.
GoPro to WiFi(page) Action Gadgets, 2019. Used GoPros can work as well as newer cams.
settings - device
repurposed cams
attendance
- meet: only in highly paid plans beginning about $12 per month (2023). The higher level educator plans also.
- zoom: only in paid plans
- teams: only in paid plans - teames is part of microsoft360 business suite
- webex: webex is inherently pay-only
Streaming and Recording(11:08) Gaming Careers, 2019. OBS based tutorial, using the computer, not a capture card.